
Experience in SYCL/oneAPI
for event reconstruction
at the CMS experiment
Heterogenous computing at the CMS experiment
In the High-Luminosity phase of the LHC (HL-LHC) the accelerator will reach an instantaneous luminosity of 7 × 1034 cm-2s-1 with an average pileup of 200 proton-proton collisions. This will lead to a computational challenge for the online and offline reconstruction software that has been and will be developed. To face this complexity online CMS has decided to leverage heterogeneous computing, meaning that accelerators will be used instead of CPUs only. To be prepared for Run 4, CMS equipped the current Run 3 production HLT nodes with NVIDIA Tesla T4 GPUs that are currently used for:
- pixel unpacking, local reconstruction, tracks and vertices
- ECAL unpacking and local reconstruction
- HCAL local reconstruction
- higher throughput thanks to the use of accelerators;
- better physics performance due to the fundamental redesign of the algorithms to fully exploit the parallelism capabilities of GPUs.
Performance portability libraries
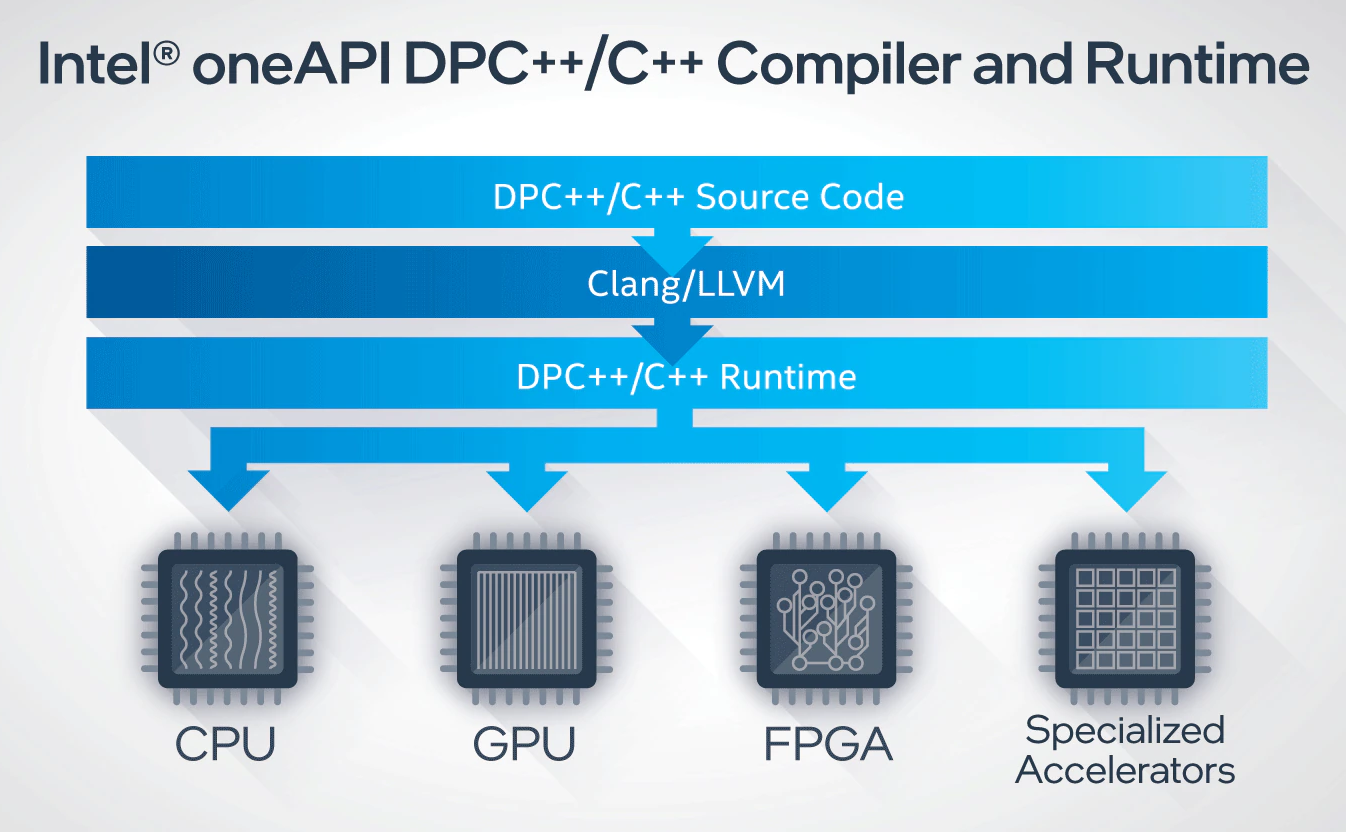
Currently, the code to be executed on GPUs is written in CUDA specifically for NVIDIA GPUs. This approach should be avoided because it would introduce code-duplication that is not easily maintainable. A possible solution is the use of performance portability libraries, that allow the programmer to write a single source code which can be executed on different architectures.
One possibility is to use Data Parallel C++ (DPC++), an open-source compiler project developed by Intel, that is part of the oneAPI programming model. DPC++ is based on SYCL, a cross-platform abstraction layer maintained by Khronos Group that allows code to be written using standard ISO C++ both for the host and the device in the same source file.
At the moment DPC++ supports:
From CUDA to SYCL
Starting from code written in CUDA, the first step in the study of SYCL/oneAPI consisted in writing a SYCL version of two algorithms:
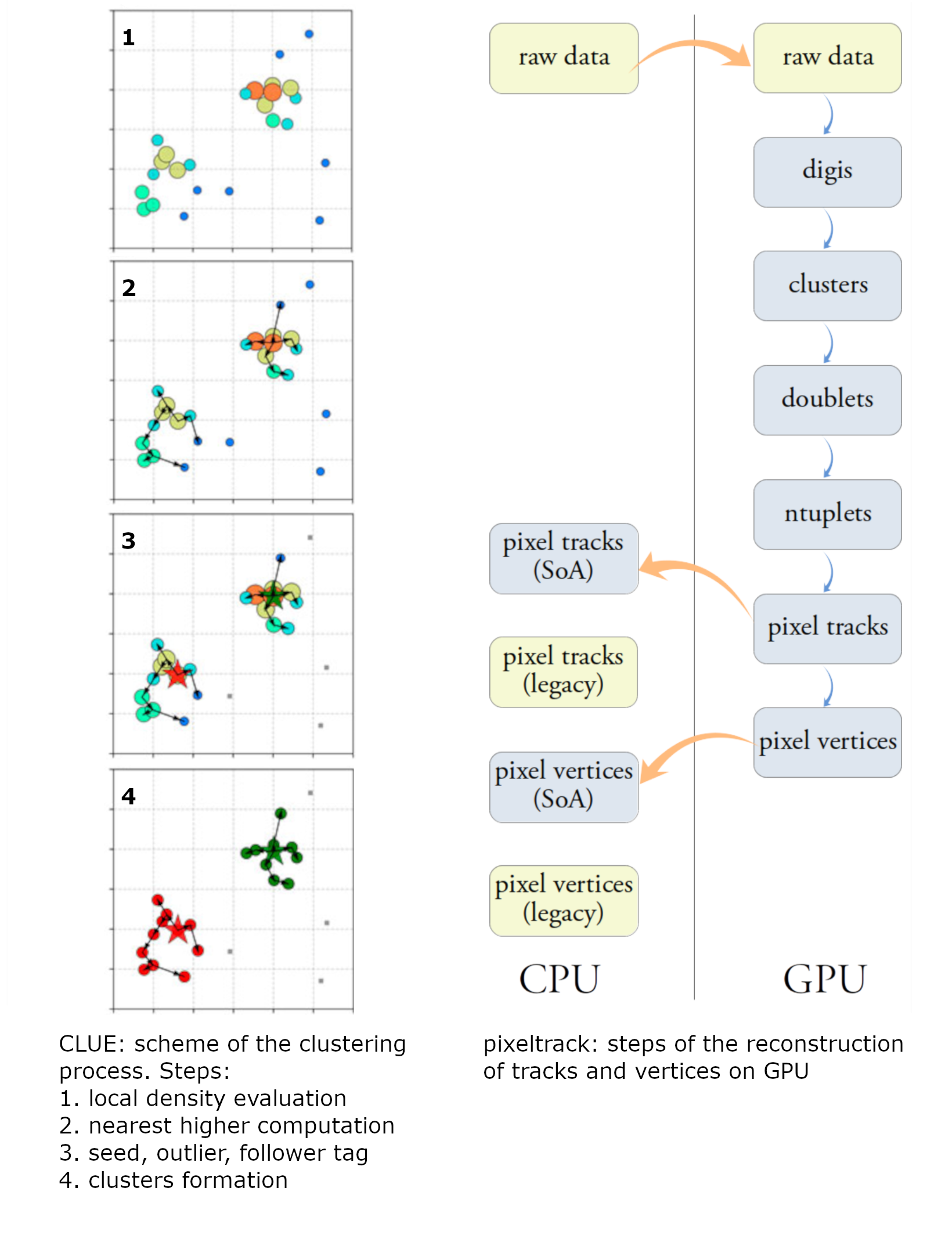
- CLUE (CLUstering of Energy): a fast parallel clustering algorithm for high granularity calorimeters that follows a density-based approach to link each hit with its nearest neighbour with higher energy density;
- pixeltrack: a heterogeneous implementation of pixel tracks and vertices reconstruction chain, starting from the detector raw data, creating clusters, then n-tuplets that are fitted to obtain tracks, used to reconstruct the vertices.
- each device is associated to a queue (analogue of a CUDA stream) that is needed to launch kernels and to do all the memory operations;
- the use of different terms (e.g. thread, block, grid become work-item, work-group, Nd range) or of the same term but with a different meaning;
- the need to avoid hardware specific code, to enhance its portability;
- some features like pinned memory are not explicitly available in SYCL as they are managed by the SYCL runtime.
Performance tests and conclusions
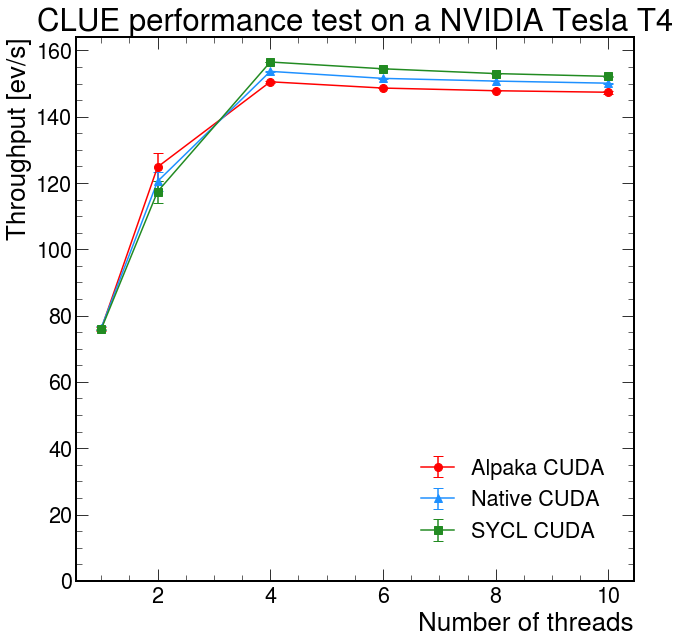
The porting of pixeltrack is still ongoing, but we are able to successfully run the code both on Intel CPUs and Intel GPUs. On the other hand CLUE has been fully ported and tested also on a NVIDIA GPU.
To carry out the tests, we used a synthetic dataset that simulates the expected conditions in high granularity calorimeters operated at HL-LHC. It represents a calorimeter with 100 sensor layers. 10000 points have been generated on each layer such that the density represents circular clusters of energy whose magnitude decreases radially from the centre of the cluster according to a Gaussian distribution with the standard deviation, σ, set to 3 cm. 5% of the points represent noise distributed uniformly over the layers.
The plots show the total throughput for different numbers of concurrent threads/streams.
- At first we tested it on an Intel Xeon Gold 6336Y CPU and an Intel GPU, showing that there is an actual gain in performance using the accelerator with respect to the traditional processor.
- Then we also tested it on a TESLA T4 NVIDIA GPU and compared its performance with native CUDA and Alpaka. The results look really promising, showing that SYCL is able to reach a throughput similar to native CUDA.
References
- CMS DAQ and HLT TDR
- pixeltrack-standalone - GitHub repo
- pixeltrack-standalone - paper
- heterogeneous clue - GitHub repo
- heterogeneous clue - paper
- porting CUDA to SYCL guide
- DataParallel C++